
The Good Internet: How Fandom Can Reclaim the Web.
This talk by Sacha Judd at FFConf was stellar. I’m in the process of finding my back to the weird web.

Under Construction
I make things on the internet
The Good Internet: How Fandom Can Reclaim the Web.
This talk by Sacha Judd at FFConf was stellar. I’m in the process of finding my back to the weird web.
Lou Montulli, a former engineer with Netscape, writes about the origins of the blink tag. It seems that it was a lament for the lack of features in text-based browsers.
Back in 1994 I was a founding engineer at Netscape, prior to that I had written the Lynx browser, which predated all of the other popular browsers at that time. Lynx had been and still is a text only browser and is commonly used in a console window on UNIX machines.
Sometime in late summer I took a break with some of the other engineers and went to a local bar on Castro street in Mountain View. At some point in the evening I mentioned that it was sad that Lynx was not going to be able to display many of the HTML extensions that we were proposing, I also pointed out that the only text style that Lynx could exploit given its environment was blinking text. We had a pretty good laugh at the thought of blinking text, and talked about blinking this and that and how absurd the whole thing would be.
Saturday morning rolled around and I headed into the office only to find what else but, blinking text. It was on the screen blinking in all its glory, and in the browser. How could this be, you might ask? It turns out that one of the engineers liked my idea so much that he left the bar sometime past midnight, returned to the office and implemented the blink tag overnight. He was still there in the morning and quite proud of it.
Why am I not surprised that the idea originated in a bar.
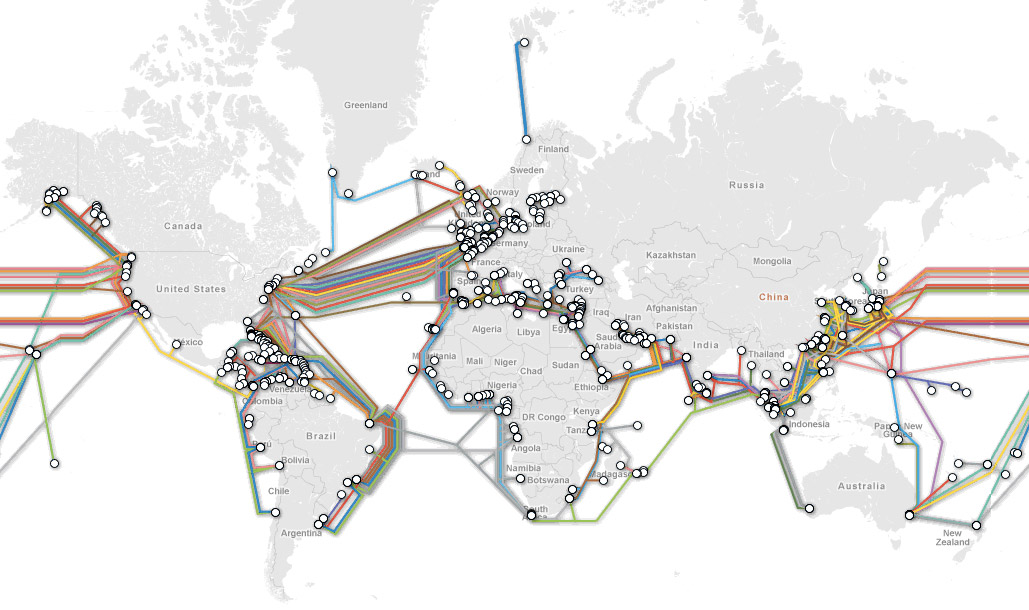
The Submarine Cable Map, just in case you wanted to know where your bits are going. Here’s an excerpt from the description of the site:
TeleGeography’s free interactive submarine cable map is based on our authoritative Global Bandwidth research, and depicts active and planned submarine cable systems and their landing stations. Selecting a cable route on the map provides access to data about the cable, including the cable’s name, ready-for-service (RFS) date, length, owners, website, and landing points. Selecting a landing point provides a list of all submarine cables landing at that station.
The source is available too.
An excerpt from Tim Berners-Lee’s post to comp.sys.next.announce concerning the release of the WorldWideWeb app:
This project is experimental and of course comes without any warranty whatsoever. However, it could start a revolution in information access. We are currently using WWW for user support at CERN. We would be very interested in comments from anyone trying WWW, and especially those making other data available, as part of a truly world-wide web.
A revolution in information access indeed.
You also might be interested in this post from the eightface archive: The oldest page on the internet.
Ben Goldacre for The Guardian on linking to the original source of material (via df).
Why don’t journalists link to primary sources? Whether it’s a press release, an academic journal article, a formal report or perhaps (if everyone’s feeling brave) the full transcript of an interview, the primary source contains more information for interested readers, it shows your working, and it allows people to check whether what you wrote was true. Perhaps linking to primary sources would just be too embarrassing.
This is one of those things that pisses me off to no end, especially with professional journalists. A couple months ago, I debunked that list of NASA bad science movies because it set off my bullshit radar. It was obvious that a list like that needed an original source if it was true. But that didn’t stop dozens of well-known news organizations from regurgitating the list without question. The web is fundamentally based on hypertext and interconnectedness, how hard is it to link to something?
Linking to sources is such an easy thing to do and the motivations for avoiding links are so dubious, I’ve detected myself using a new rule of thumb: if you don’t link to primary sources, I just don’t trust you.
That rule goes for everyone, not just journalists… give credit where credit is due. Users of Tumblr and Ffffound are particularly bad in terms of original sources. If I come across something I like on one of those sites, it usually takes considerable effort to discover who actually made it.
Of course, with all of the link sharing that goes on, we get another problem: sourcing sources, or indicating where you discovered your link. Justin Blanton was lamenting the lack of “via’s” today. It gave me a tinge of linker’s guilt, because I’ve borrowed his links on more than one occasion without credit. Vias are one of those things that I tend to be bad with — it’s often a result of having more than thirty tabs open and not remembering where they all originated. Sure, it’s not as important as linking to the original but a little link-love never hurts.

It’s possible that we may see work from the old Swanky and Swankarmy crew — the old archives have been found. From a tweet by Dustin Vannatter:
I found a series of 20+ CDs that contain a fs dump of all Oh, Hello projects inc Scribble.nu and Swanky.org .. going to try to restore it.
Swanky was one of the first design communities on the internet in the late nineties. They were heavily inspired by the work of David Carson; a lot of grunge and distorted typography. It wouldn’t be a stretch to say that it was an influence on a huge number of designers. Scribble was a journal site, a sort of precursor to weblogs.
I found the scene in 1998 when it was beginning to implode. Still, Swanky was one of the reasons I started getting interested design. It also led to my discovery of typography and the creation of a bunch of crappy typefaces, before realizing that it took a lot of effort to make a good one. I was never a member of Swanky, but ended up forming Suffocate.org with a number of ex-members. We had themed issues and a number of side-projects — including the Conform Project, which was similar to Layer Tennis. Most of my Suffocate work is lost, but I found some of the early Conform series in an old archive, and posted them a few years back.
I’d love to see the old Swanky stuff, brings back a lot of memories. As for Scribble, I don’t know if the world needs my high-school ramblings, but it could be an interesting historical archive.
Colm O’Regan examines the constant stream of things that demand our attention. I’m not sure if he made up divided attention disorder, but I was amused by the analogy to tabbed browsing.
It’s the equivalent of sitting on the floor of a library desperately trying to remember what I was looking for with 20 books open around me, unable to concentrate because people keep giving me a thumbs up to tell me they “Like This”.
Update: It appears that Esquire had an article about DAD in a recent issue, but the full-text isn’t online.

Randall from xkcd has posted an updated version of the Map of Online Communities for 2010. It’s also available full size for extra goodness.

The Original Marble & Granite Co. Ltd. is based out of Hoddesdon in Hertfordshire. They don’t have a website and are probably not aware of the sheer internet greatness of their name.
The photo was taken with my crappy phone camera on the way home for work the other day.
Update: Actually, I think this might be their website.
John Goerzen has archived Gopherspace (all 40gb) and made it available as a 15gb compressed torrent. Gopher was around in the 1990s before the World Wide Web, it was similar, but not hyperlinked. I remember using Gopher in high-school, it was the first time I ever came across the
A Tool to Deceive and Slaughter is a piece of artwork by Caleb Larson that perpetually tries to sells itself.
Every ten minutes the black box pings a server on the internet via the ethernet connection to check if it is for sale on the eBay. If its auction has ended or it has sold, it automatically creates a new auction of itself.
Know Your Meme, just in case you were confused by the internet. You may also want to read I can has rezearch papar? I did it for the lulz.